演习变成实战
去年11月份,我写过一篇《混合云监控架构:Prometheus + VictoriaMetrics 实现数据容灾》,提出了“云端短期采集 + 本地长期存储”的容灾架构。
后来我对此架构有做了一些升级。而就在昨天,我恰好真实经历了一次“灾难”。
昨天,我给本地机房的运行 VictoriaMetrics 的 Ubuntu 虚拟机从 AMD 宿主机热迁移到 Intel 宿主机时,因跨厂商指令集缓存冲突,系统直接爆出 Kernel Panic,网络层也彻底瘫痪。本地机房的 Metrics 核心存储节点,这下给宕机了。
但这并不是一篇“删库跑路”的检讨书。相反,我的告警系统依然稳稳的,所有监控数据照常查询,所有告警都能正常播报。
1. 架构演进:为什么用 VMAgent 替换 Prometheus?
在上一版架构中,云端使用的是 Prometheus 作为采集和短期存储。但在今年的架构演进中,我将采集层全部替换为了 VictoriaMetrics 家族的 vmagent。
1.1 替换的核心逻辑
- 极致轻量:vmagent 移除了本地 TSDB 查询引擎,内存和 CPU 占用仅为 Prometheus 的三分之一。
- 原生的磁盘缓冲:这是今天救命的关键。当后端存储不可用时,vmagent 会自动将数据写入本地磁盘暂存,网络恢复后自动断点续传。
- 兼容Prometheus:原生兼容 Prometheus 配置,且推送性能极强。
1.2 当前混合云容灾拓扑
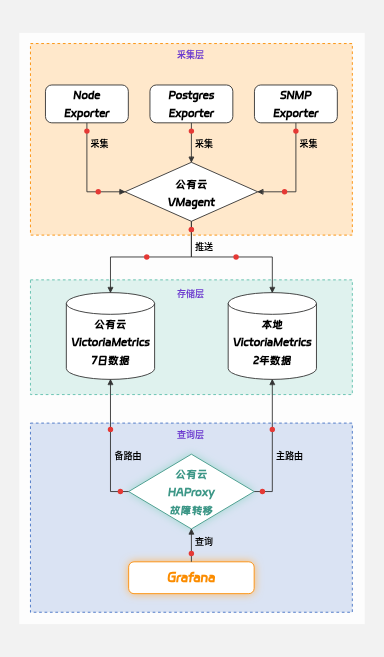
这套监控架构的核心设计思想是:写入端强解耦,查询端高可用,存储端冷热分层。
1. 采集端:vmagent 统一抓取与缓冲
- 集中采集:所有监控目标(Node Exporter、应用服务业务指标等)统一由部署在公有云的
vmagent实例定时抓取。
- 断点续传:为应对跨网络传输的不确定性,我们在
vmagent层面配置了 5GB 的本地磁盘缓冲(Disk Buffer)。按照我们当前的指标体量,这 5GB 缓冲足以兜底长达 24 小时的机房网络中断或节点宕机。
2. 数据流向:异地实时双写 (Geo-Dual-Write)
vmagent 在获取到数据后,不进行任何本地积压,而是立刻开启并行 Remote Write,将指标数据同时写入两个异地存储节点。一旦任意一端写入失败,会将失败的数据块暂存入上述的 5GB 队列中等待节点上线重发。
3. 存储层:冷热数据分层 (Data Tiering)
- 云服务器(短期兜底数据池):部署 VictoriaMetrics 节点,仅保留最近 7 天 的数据。它成本可控,网络极其稳定,主要作为兜底保障,当本地指标存储服务器宕机时,依然保障最近一周的指标数据可供临时故障分析使用。
- 本地机房(主数据湖):部署大容量的 VictoriaMetrics 节点,保留长达 2 年 的全量历史数据,同时本地 cpu 性能更强、内存更多,能承载更多复杂频繁查询。
4. 查询层:基于 HAProxy 的自动故障转移 (Auto-Failover)
- 主备路由机制:为了对外提供一个单一且高可用的数据源,我们在云端引入了
HAProxy作为查询网关。Grafana 的所有查询请求都直接发往 HAProxy。
- 平滑降级:在正常状态下,HAProxy 会将读请求 100% 路由到本地机房的主节点(Primary),确保能查到最全的数据;当本地机房发生物理级宕机时,HAProxy 会瞬间感知并将流量无缝切换至云端的备用节点(Fallback)。此时系统进入平滑降级状态——虽然只能查询近 7 天的数据,但保证了核心监控面板不报错,告警引擎持续运转。
2. 故障复盘:平滑降级与断点回填
- 宕机瞬间系统平滑降级
当本地机房节点 Kernel Panic 离线后,vmagent 立即探测到 xxx.xxx.xxx.xxxx:8428 无法路由。但在监控终端,和告警播报端毫无感知。
得益于我们的高可用网关设计,当底层检测到本地节点不可用时,触发了自动故障转移(Auto-Failover)。Grafana 的数据源查询请求无缝 Fallback 到云端的 7 天热数据节点。虽然无法查看去年的历史数据(平滑降级),但最近 7 天的面板和所有实时的告警规则依然精准触发。告警引擎,零延迟,零宕机。
- 2.1GB 数据的幕后积压后写回
机房宕机这几个小时,vmagent 在云端默默扛下了所有。它迅速启用了配置中的 -remoteWrite.tmpDataPath,将原本要发往厦门机房的数据全部转存到云服务器的本地磁盘。
当我将虚拟机关机重新冷启动,恢复本地节点后,打开 Grafana 看板,可以看到 HAProxy 已经将查询流量切换到了本地节点,看板上的指标线条,虽然有着一整晚十个多小时的空白,但是却正在一点一点的往右增长,那是 VMAgent 在将数据写回。
稍作等待,再刷新看板,发现数据已经完全刷写完成了。